Background
Our website has stock quotes. We have two fast connections to the Toronto Stock Exchange (TMX) which we use to get stock data for the TMX, TMX Venture, Nasdaq, and NYSE (as well as several affiliate stock exchanges, such as Nasdaq OMX/PHILX, NYSE Arca, etc). We also get index data from Dow Jones and Standard and Poors. The data feed we receive gives us data in real time (with incredibly low latency). However, for most of our customers, we need to delay the data by varying numbers of seconds.
Because of the need to delay the data, we need to store our incoming stock information somewhere. We've used a certain major relational database and we had a third party company build us a really nifty in-memory distributed system which processes the data, optionally delays it and makes it available through a REST-like web service. The third party in-memory solution was necessary because we found that the relational database simply couldn't keep up with the stock feed. The problem with the third party in-memory solution is that it was written in 32-bit Visual C++, and we are mostly a java shop. When the solution was originally done (over 10 years ago), we felt that java simply couldn't deliver the speed necessary to process incoming stock data.
A Possible Solution with Java and Cassandra
As Enterprise Architect, I was able to completely re-think the way we process stock data. I met with some of the people who were responsible for providing operations support and they pointed out to me that our stock data vendor actually had a java api, which suggested that perhaps java was now fast enough. There was still the matter of how to store the stock data so that we could delay it. Obviously, an custom in-memory solution was a possibility, which might have essentially become a java rewrite of the C++ system. There are several java in-memory libraries/databases that we might have used (or we could have just used standard java data types), however, given our recent experience with Cassandra, I wondered if it would work. Cassandra was attractive in that it was fairly easy to build a cluster that actually works across data centres and which can survive the total failure of one or more servers. This was important to us because our stock data system needed to have no single points of failure and, traditionally in our organization, our database had been a single point of failure.
Cassandra's Weird Data Model
We started this project back in 2011, and there wasn't a whole lot written about how to do data modelling in Cassandra. We needed to figure out how to put stock data into Cassandra, but it soon became clear that Cassandra's data model was a bit difficult. I found "WTF is a supercolumn" to be a really helpful starting point, even though it is a bit outdated now. If you are just starting with Cassandra, you should make sure you install the latest version and read something on the DataStax site, such as this documentation.
You might wonder why Cassandra's data model is so weird (as have many of the developers who work at my company). The most important thing to understand is that Cassandra really is a distributed database. This means that:
- Your data set can be spread over multiple servers (also known as sharding)
- Any given piece of data can be on more than one server, which gives Cassandra the ability to load balance requests and recover from server failures.
Distributed databases need to make certain trade offs. Cassandra, like many of them, does not support joins. It also has to make trade offs between consistency, atomicity and partition tolerance, as predicted by Brewer's theorem. Indexing is also somewhat limited.
To make matters more challenging, Cassandra has it's own terminology:
What relational databases call a "schema", Cassandra calls a "keyspace". What relational databases like to call a table, Cassandra calls a "column family". It's probably fair to give these things different names in Cassandra, given that they are not really exactly the same as what you get in a relational database. However, it does make for a steeper learning curve.
The first point that I learned about Cassandra data modelling is that because there are no joins, you have to de-normalize everything. That means that all the information for a given query pretty much needs to go into one column family. As a result, you really need to think backwards from your queries and make sure that there is a single column family that satisfies them (or, as a last resort, do joins in your code).
The next thing I learned about Cassandra is that you really need to think of columns differently than you do in a relational database. In a relational database, every row generally has the same columns (although people have found various ways to get around this, often by using varchar fields to hold string values of arbitrary data types). In Cassandra:
- every row can have completely different columns,
- every row can have a lot of columns (up to two billion)
- the columns are essentially sorted in order by their name and so it is possible to (quite efficiently) retrieve ranges of columns in a specific row using a single query
The last point is really important and effectively determines the data structures that a Cassandra column family can represent. It also means that, if you want to do any kind of range queries, the data for the range query needs to fit into a single row. Because Cassandra rows are not necessarily stored on the same node, you can't effectively do a range query over several rows.
So, what data structure does a Cassandra column family represent? I tend to think of it as follows:
A Cassandra column family is analogous to a distributed java hashtable, keyed by row (or primary) key. Each row can be stored on a completely different server in the Cassandra cluster and may in fact be replicated on several servers (depending on how you configure your replication settings). The "value" in this distributed hashtable is essentially another hashtable, whose keys are the names of the columns in a row. These columns can be individually retrieved or can be retrieved by specifying the start and end column name for the range of columns that you want to fetch. As you may have just guessed, columns in each row are kept sorted by their column name (you can define the sort order by specifying a java comparator). The hardest thing about Cassandra data modelling, for those of us that came of age on relational databases, is that you can (and usually should) have a large number of columns in a single Cassandra row. Cassandra rows can contain up to about 2 billion columns, so there is no need to try and keep the number of columns in a row small.
I think that thinking of Cassandra as a distributed hashtable with values that are hashmaps is useful for understanding the capabilities of the storage engine. However, this article makes a very good argument that Cassandra should normally be conceptualized differently.
On a conceptual level (for the architects out there that don't want to wade into the weeds), Cassandra rows can contain at least the following:
.png) |
| A Cassandra column family is conceptually a distributed hashmap which maps row keys to rows, which are themselves hashmaps in which a column name is mapped to a value. Each row can be on a different server and may in fact be on more than one server (not represented in the above diagram), depending on your replication settings. |
On a conceptual level (for the architects out there that don't want to wade into the weeds), Cassandra rows can contain at least the following:
- Single values, that are accessed by individual column keys. This is a lot like a relational database. For example, a column family that contains addresses might have one row with the columns: name, house number, street name, street direction, city, state, zip code, country (for a U.S. address, for example) and another row with the columns name, house number, street name, street direction, city, province, country, postal_code (for a Canadian address). Let's assume that this column family is used inside some sort of customer management application, and therefore, in addition to the columns above, each row would have an additional column, customer_number, which would be used as a row key. Don't forget the row (aka primary) key when you design Cassandra column families. Unlike relational database tables, every row must have a (primary) key in a Cassandra column family.

Two row in a customer column family. Notice that the columns are slightly different in each. - Lists or sets of values. For example, you may wish to store a list of phone numbers for each customer in the customer column family we talked about above. Unlike a relational database, you'd probably store a list of phone numbers in the same row as you stored the rest of the address information, instead of de-normalizing it and putting it somewhere else. Sets are really just lists in which every element can occur at most once (and in which the order of the elements is not important, so technically the "list: of phone numbers just mentioned is more properly called a "set" of phone numbers). Recent versions of Cassandra (see the datastax documentation for more details) support high level abstractions for storing lists and sets inside rows. If you aren't using a recent version, or like to do everything yourself, you can create lists and sets fairly easily by using composite columns or by just creating a column name that is the name of the list or set concatenated to a fixed width number representing the element's position in the list (in the case of a list) or to a string representation of the set element (in the case of a set).
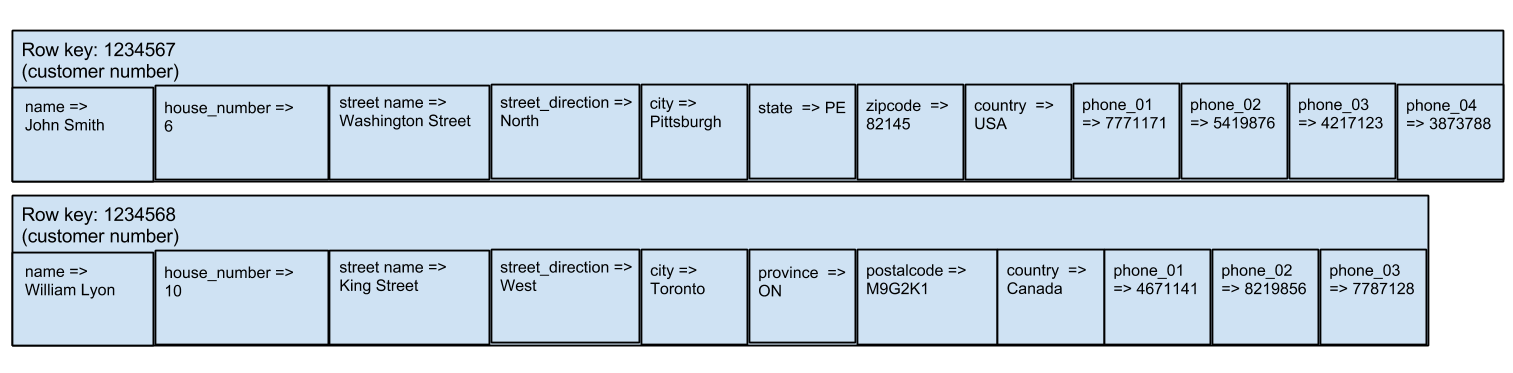
Our customer data with a list of phone numbers added. The phone numbers are in columns named phone_xx, where
xx is a two digit number. There could be some concurrency issues with adding phone numbers using this technique if two different threads/servers try to append a phone number at the same time with the same index. This could be avoided by appending a globally unique identifier (possibly server name + pid) for the thread to the column name. If we wanted to store a set of phone numbers, instead of list, the column name could be phone_<phone number>. - Time series. A time series is just a special type of list in which elements are always kept in order by time stamp. If you create the column names using time stamps and make sure that your column comparator will sort the time stamps in chronological order, you have a very useful time series capability. You can use the Cassandra column slice feature (which takes a start row and end row name and retrieves all the columns whose name fall into the resulting range) to retrieve all the columns that occur in a specified time interval. You can use a reverse column slice to retrieve the columns in reverse chronological order (most recent first). This is often very useful. In our customer column family which we talked about in the above two cases, we could add a time series to keep track of customer contacts. The column names could be something like "contact" concatenated to a the date/time of the contact and the contents of the column could be a piece of text describing the customer contact.

Adding a time series of customer contacts to our customer records by using a column name that is contact_<timestamp>. The most important thing for time series columns is that they sort properly in (reverse) chronological order so that column slices are useful. Notice that we can put basic address information, a telephone number list and a custom contact time series easily in the same column family. - Combinations. As implied in the above cases and diagrams, it is possible to combine any or all of the above into a single row, if you are careful about defining the column comparator, which determines how the columns are sorted. You must define a column comparator that works in all the rows of a given column family, and therefore sorts all the columns the way you want them sorted so that any column slice queries will retrieve the correct columns in the correct order. Often, it is simplest to use a a very basic comparator for your columns, which will sort them in String or byte array order and then build your column names so that the sorting will be correct.
CQL3 In Cassandra 1.2+: Radical Change comes to Cassandra Data Modeling
Cassandra 1.2+ has many improvements over Cassandra 1.1, including virtual nodes and more off heap data structures (which allows more data to be stored per node). CQL3 is a really important change in Cassandra 1.2+. CQL stands for "Cassandra Query Language" and it is essentially an SQL-like language for Cassandra. It has been available since Cassandra 0.8. CQL provides another (besides the thrift API) way to query and/or store data in Cassandra which is easier for many developers to learn.
Up until CQL3, it was a bit awkward using CQL for Cassandra column families that had rows that contained many columns (that is, the time series, list, sets and maps cases described above). CQL3 puts a much more high level interface on the Cassandra storage engine that many developers will likely find easier to understand.
CQL3 adopts a different terminology than was prevoiusly used to describe data modelling in Cassandra. CQL3 now talks about "partitions" instead of "rows" and "cells" instead of "columns". CQL3 also allows special types of columns that store maps, lists and sets, which takes care of the most common reasons for wide rows. I still think an explicit time series column type would have been nice, but you can essentially get that by using a time stamp as part of a composite primary key (just don't use it as the first component!).
CQL3 introduces the concept of composite primary keys, which is a primary key that consists of several fields, such as "newspaper_issue_date, edition, page_number". From reading the (highly recommended) DataStax documentation, it appears that the first field in the composite key is used as what we used to call a "row key" and the remaining fields' values are used to build names for composite columns.
It was not immediately clear to me how fields that are not part of the composite key are actually stored when there is a composite key, given that these fields can be indexed using secondary indexes. I investigated by setting up a table in Cassandra 1.2.5 as follows (using cqlsh):
create table test1 ( listing_id_and_date TEXT, trade_time int, price float, low float, high float, close float, PRIMARY KEY( listing_id_and_date, trade_time ) );
I then added three rows (again using cqlsh):
INSERT INTO test1(listing_id_and_date, trade_time, price, low, high, close) values ('21221.20131202', 123, 12.50, 12.00, 13.00, 12.75);
INSERT INTO test1(listing_id_and_date, trade_time, price, low, high, close) values ('21221.20131202', 124, 22.50, 22.00, 23.00, 22.75);
INSERT INTO test1(listing_id_and_date, trade_time, price, low, high, close) values ('21221.20131202', 125, 32.50, 32.00, 33.00, 32.75);
I then used cassandra-cli to see how the storage engine is actually storing the above three rows:
RowKey: 21221.20131202
=> (column=123:, value=, timestamp=1372439472065000)
=> (column=123:close, value=414c0000, timestamp=1372439472065000)
=> (column=123:high, value=41500000, timestamp=1372439472065000)
=> (column=123:low, value=41400000, timestamp=1372439472065000)
=> (column=123:price, value=41480000, timestamp=1372439472065000)
=> (column=124:, value=, timestamp=1372439524262000)
=> (column=124:close, value=41b60000, timestamp=1372439524262000)
=> (column=124:high, value=41b80000, timestamp=1372439524262000)
=> (column=124:low, value=41b00000, timestamp=1372439524262000)
=> (column=124:price, value=41b40000, timestamp=1372439524262000)
=> (column=125:, value=, timestamp=1372439550103000)
=> (column=125:close, value=42030000, timestamp=1372439550103000)
=> (column=125:high, value=42040000, timestamp=1372439550103000)
=> (column=125:low, value=42000000, timestamp=1372439550103000)
=> (column=125:price, value=42020000, timestamp=1372439550103000)
It was not immediately clear to me how fields that are not part of the composite key are actually stored when there is a composite key, given that these fields can be indexed using secondary indexes. I investigated by setting up a table in Cassandra 1.2.5 as follows (using cqlsh):
create table test1 ( listing_id_and_date TEXT, trade_time int, price float, low float, high float, close float, PRIMARY KEY( listing_id_and_date, trade_time ) );
I then added three rows (again using cqlsh):
INSERT INTO test1(listing_id_and_date, trade_time, price, low, high, close) values ('21221.20131202', 123, 12.50, 12.00, 13.00, 12.75);
INSERT INTO test1(listing_id_and_date, trade_time, price, low, high, close) values ('21221.20131202', 124, 22.50, 22.00, 23.00, 22.75);
INSERT INTO test1(listing_id_and_date, trade_time, price, low, high, close) values ('21221.20131202', 125, 32.50, 32.00, 33.00, 32.75);
I then used cassandra-cli to see how the storage engine is actually storing the above three rows:
RowKey: 21221.20131202
=> (column=123:, value=, timestamp=1372439472065000)
=> (column=123:close, value=414c0000, timestamp=1372439472065000)
=> (column=123:high, value=41500000, timestamp=1372439472065000)
=> (column=123:low, value=41400000, timestamp=1372439472065000)
=> (column=123:price, value=41480000, timestamp=1372439472065000)
=> (column=124:, value=, timestamp=1372439524262000)
=> (column=124:close, value=41b60000, timestamp=1372439524262000)
=> (column=124:high, value=41b80000, timestamp=1372439524262000)
=> (column=124:low, value=41b00000, timestamp=1372439524262000)
=> (column=124:price, value=41b40000, timestamp=1372439524262000)
=> (column=125:, value=, timestamp=1372439550103000)
=> (column=125:close, value=42030000, timestamp=1372439550103000)
=> (column=125:high, value=42040000, timestamp=1372439550103000)
=> (column=125:low, value=42000000, timestamp=1372439550103000)
=> (column=125:price, value=42020000, timestamp=1372439550103000)
As expected, the first component of the composite key is used as the row key. The value of the second component is used as the first part of the column name for the remainder of the columns (see the red text above) and is followed by a colon to separate it from the second part of the column name. The cell name (for fields that are not part of the primary key) specified in the create table statement is used as the second part of the column name (see brown text above). There is also a column that just has a name which is the second component of the primary key, followed by a colon and has no column value.
It turns out that there is an option "WITH COMPACT STORAGE" that you can use when creating a table in CQL3 when the table has only one cell that is not in the primary key. When you use this option, the first component of the primary key is used as a row key, the second and subsequent components are concatenated together and used as the column name and the column value is the single cell not in the primary key.
In a sense, CQL3 flips things around a bit conceptually to hide the fact that range queries can only be done on columns within a row (using the terms in the old sense). It does probably make Cassandra more accessible to people who are used to relational databases. There is a slight danger in CQL3 in that not everything that someone who has an SQL background intuitively thinks should work will actually work.
The remainder of this blog entry uses the old terminology to describe Cassandra column families that contain stock data. However, it is possible to rather easily map this to the new CQL3 way of thinking used in Cassandra 1.2+. All of the stock data column families described below have a row key which identifies the row. Each row has a large number columns whose column name is generally a timestamp or a timestamp concatenated to something (like volume).
So, it is possible to use CQL3 syntax to describe any of the stock data column families below. The general pattern would be something like this:
create table <column_family_name> ( <row_key> text, <column_name> text, price_information text, PRIMARY KEY (<row_key>, <column_name>) ) WITH COMPACT STORAGE;
The remainder of this blog entry uses the old terminology to describe Cassandra column families that contain stock data. However, it is possible to rather easily map this to the new CQL3 way of thinking used in Cassandra 1.2+. All of the stock data column families described below have a row key which identifies the row. Each row has a large number columns whose column name is generally a timestamp or a timestamp concatenated to something (like volume).
So, it is possible to use CQL3 syntax to describe any of the stock data column families below. The general pattern would be something like this:
create table <column_family_name> ( <row_key> text, <column_name> text, price_information text, PRIMARY KEY (<row_key>, <column_name>) ) WITH COMPACT STORAGE;
Representing Stock Data In Cassandra
The Requirements
Our stock feed sends us events, which are essentially notifications that something about a stock, index or currency has changed, often the price. We have a java daemon that receives these events and decides what to store into Cassandra. Recall that you need to consider your queries when you build Cassandra column families. In our case, we need to support three main types of queries:
- A query to get the most recent price for a particular stock, index or currency for users that have access to real time quotes. Similarly, we need to be able to retrieve the latest price that is at least n seconds old, for users that are only allowed to see delayed quotes. We designed a column family called Quotes to satisfy these two queries.
- A query to return the all the one minute intervals for a given stock, index or currency that are between two specific times in a given day. An interval is a tuple that has the opening price, closing price, high, low and volume for a given one minute period. These are used to construct various types of charts. We designed a column family called IntervalQuotes to satisfy queries of this type.
- A query to return all the price changes between a certain start and end time for all stocks, indexes and currencies. We use this query to get data to update a solr core that contains current prices. The program that does the updating wakes up periodically and requests all price changes since it last ran, and then updates only the stocks, indexes or currencies that have changed. Since many stocks trade very infrequently, updating only the what has changed is a very effective optimization. We built a column family called TimeSortedQuotes to satisfy these queries.
The Column Families
Background -- listing_ids, trades and ticks
We have created a special number, called a listing_id for each stock, index or currency for which we receive data. When a user types in a stock symbol, listing symbol or currency pair, we map it to the appropriate listing_id and then use it to do any queries. The advantage of this is that stocks, indexes and currencies all look identical after you get past the upper levels of our code. Doing this also allows us to transparently handle providing historical data when a company changes stock symbols -- the price data continues to be stored under the same listing_id and no special logic is required.
Our stock feed data tends to send us updates in two possible circumstances. The first circumstance is a trade, in other words when a stock is sold to a buyer. The second circumstance, which generally applies to indexes, is when a tick occurs. Ticks are just the price of a security (often a security that doesn't trade, such as an index) and associated information such as volume, open, high, low and close, at a given moment in time. Index ticks often come at regular intervals. For example, we receive ticks for the S&P500 index every five seconds from market open until about an hour after market close.
Our stock feed data tends to send us updates in two possible circumstances. The first circumstance is a trade, in other words when a stock is sold to a buyer. The second circumstance, which generally applies to indexes, is when a tick occurs. Ticks are just the price of a security (often a security that doesn't trade, such as an index) and associated information such as volume, open, high, low and close, at a given moment in time. Index ticks often come at regular intervals. For example, we receive ticks for the S&P500 index every five seconds from market open until about an hour after market close.
Quotes
The Quotes column family is intended to support queries for delayed and real time stock quotes, as described in #1 in the above list. For our purposes, a stock quote is the price of the stock, along with some other information, such as bid, ask, open, high, low, close, and cumulative volume. We can put all of this information into a single Cassandra column if we want by serializing it using a method such as JSON. If you are used to relational databases, having multiple values in a single column probably seems to be a bit weird. Remember though that we cannot do a range query over multiple rows and that time series data needs to be stored as columns in a single row. This means that we cannot break out the various fields in a stock quote into single columns, but instead we need to have all the fields for a single quote in a single column. We will construct the column names using a time stamp concatenated to the current cumulative volume and we will generally only write new columns when our stock feed tells us that there is a new trade or a new tick (for indexes). You might wonder why we use the volume as part of the column name, when we are constructing a time series that should really only need a time stamp. The reason is that sometimes two stock trades have precisely the same time stamp, so we use cumulative volume to break the tie.
If we restrict a given row to only contain the information for a single listing_id, we can satisfy a stock quote query for a given listing_id by going to its row and then doing a range (column) slice, specifically a reverse slice, which returns the columns in reverse chronological order. To do a real time query, we can get the most recent column in the row by using a column slice from the end of the current day until the start of time, specifying that we want only the first column in the slice. To do a delayed query, we change the start of the slice to (now - delay_value + 1ms) (and specify a cumulative volume of zero) and again only request the first column in the slice. We use a cumulative volume of zero because it is normally impossible and therefore guarantees that the column returned can be no more recent than now - delay_value (think of the way that the columns are sorted -- first by time stamp and then by cumulative volume -- and you will see how this works).
We ended up making a tweak to the above design: instead of using listing_id as the row key, we used listing_id concatenated to date as the row key. We originally did this because we were concerned about having really wide rows (that is, rows with huge numbers of columns). We were also concerned that stocks that trade frequently would always end up on the same servers. By putting the date in the row key, in means that the quotes for a given stock end up in a different row each day and therefore potentially on a different server each day. This tweak makes retrieving quotes a little less straightforward because we need to check the previous dates if we don't find a quote for a given stock for the current day. In practice, we find that this isn't a huge problem -- it doesn't make our code much more complex and it doesn't seem to create an performance issues.
One thing we added to the above design is time to live values for stock quote columns. We currently use a TTL of five days, which keeps the Quotes column family of manageable size. The only drawback with setting a TTL on a stock quote is that some stocks trade less frequently than every five days and consequently we won't be able to display a quote for them. We solved this problem by creating another column family that contains the last known quote for each listing_id. If we can't find a quote in the Quotes CF, we use the last known quote.
If we restrict a given row to only contain the information for a single listing_id, we can satisfy a stock quote query for a given listing_id by going to its row and then doing a range (column) slice, specifically a reverse slice, which returns the columns in reverse chronological order. To do a real time query, we can get the most recent column in the row by using a column slice from the end of the current day until the start of time, specifying that we want only the first column in the slice. To do a delayed query, we change the start of the slice to (now - delay_value + 1ms) (and specify a cumulative volume of zero) and again only request the first column in the slice. We use a cumulative volume of zero because it is normally impossible and therefore guarantees that the column returned can be no more recent than now - delay_value (think of the way that the columns are sorted -- first by time stamp and then by cumulative volume -- and you will see how this works).
We ended up making a tweak to the above design: instead of using listing_id as the row key, we used listing_id concatenated to date as the row key. We originally did this because we were concerned about having really wide rows (that is, rows with huge numbers of columns). We were also concerned that stocks that trade frequently would always end up on the same servers. By putting the date in the row key, in means that the quotes for a given stock end up in a different row each day and therefore potentially on a different server each day. This tweak makes retrieving quotes a little less straightforward because we need to check the previous dates if we don't find a quote for a given stock for the current day. In practice, we find that this isn't a huge problem -- it doesn't make our code much more complex and it doesn't seem to create an performance issues.
One thing we added to the above design is time to live values for stock quote columns. We currently use a TTL of five days, which keeps the Quotes column family of manageable size. The only drawback with setting a TTL on a stock quote is that some stocks trade less frequently than every five days and consequently we won't be able to display a quote for them. We solved this problem by creating another column family that contains the last known quote for each listing_id. If we can't find a quote in the Quotes CF, we use the last known quote.
 |
| The Quotes family for storing stock quotes. The row key is the listing_id concatenated with the date, meaning that each row stores the quotes for a particular stock for a particular day. The column names are timestamps concatenated with the volume, in order to deal with the situation in which the price changes for a stock several times within a millisecond. The volume is preceded by a letter of the alphabet which essentially gives the number of digits in the volume (A means one digit, B means two, C indicates three digits, etc). This is done so that the volume will sort in the correct order using a String comparator. The actual stock price information in each column is just a big blob of text that is constructed to be easily parseable. |
Interval Quotes
The interval quote column family stores the open, high, low, close and volume for a given stock or index over a period of one minute. The information is normally used to create intra-day stock charts, namely charts of intervals smaller than one day -- in our case, one minute, five minute, 15 minute and 1 hour. Intervals of longer than one minute are produced by combining the necessary number of one minute intervals together.
Each row in the column family stores the one minute intervals for a given stock/index for a given day. The row key is just the date concatenated to the listing_id for the index or stock. The column keys are the start time for the interval. Each column is essentially a composite data structure which stores the open, high, low, close and volume values. We keep interval data "forever" therefore there is no time to live set on the rows or columns. The interval data is sparse in that there is no interval stored for a stock if there is no trading for that stock in a given minute. This makes it a bit more complicated to process as the non-existent intervals need to be reconstructed in the software that does the querying (we have a DAO which takes care of this).
We need to be able to read the interval data as quickly as possible in order to accommodate web pages with several hundred charts. Cassandra stores the columns belonging to the same row in sorted order on disk (and therefore in the OS disk cache). We have found that the most important factor in determining how fast the data is read is the size of the data. Therefore, having sparse intervals is a big win. Keeping the column values as compact as possible also helps and Cassandra's ability to do compression makes a big difference. Because interval quote information does not change after the interval has finished, caching is very effective. We cache frequently accessed stocks in application server memory and only use Cassandra to retrieve the intervals not already in the cache.
We need to be able to read the interval data as quickly as possible in order to accommodate web pages with several hundred charts. Cassandra stores the columns belonging to the same row in sorted order on disk (and therefore in the OS disk cache). We have found that the most important factor in determining how fast the data is read is the size of the data. Therefore, having sparse intervals is a big win. Keeping the column values as compact as possible also helps and Cassandra's ability to do compression makes a big difference. Because interval quote information does not change after the interval has finished, caching is very effective. We cache frequently accessed stocks in application server memory and only use Cassandra to retrieve the intervals not already in the cache.
 |
| The interval quotes column family, which stores open, high, low, close and volume for one minute intervals for a given stock or index. As in the Quotes column family, the row key is the listing_id concatenated with the date, meaning that each row stores intervals for a given stock or index for a given day. The column names are time stamps which are the start of the interval that the column represents. The column is a text blob that is constructed to be easily parseable. If there are no trades during a one minute interval for a given stock, then there is no column for that interval. Keeping the column family sparse is a performance enhancement -- essentially smaller rows can be accessed more quickly. |
Time Sorted Quotes
We have a stock screener application that allows users to determine which stocks meet a set of chosen criteria. I won't go into the details of how this works (perhaps in another blog entry!), however it uses a solr core and needs to store current stock and index prices in that solr core. The latest version of solr (solr 4, aka "solr cloud") is quite good at real time updates, so it is possible to frequently populate recent stock prices in a solr core.
The problem is that we have about 15,000 stocks whose price we potentially need to update. Even if we can query Cassandra for each stock price in about 2-3 ms (which is possible), the querying alone would take about 30-45 seconds, which is far too long when you need to provide real time stock prices. It would be possible to use multiple threads to query Cassandra and shrink this time considerably (parallel queries can work very well in Cassandra when you have more than one node in your cluster as your parallel queries potentially go to separate servers). However, we'd still have to update solr with 15,000 prices and, even with multiple threads, we would likely need more time than is ideal.
Fortunately, there is no real need to query Cassandra for 15,000 stock prices for each solr core update. Although a few stocks trade hundred of times per second and therefore have frequent price changes, most stock prices do not change often. We only need to update the prices of stocks that have changed since the last update, which is generally not a large number when the updates occur frequently.
The Time Sorted Quotes column family is used to query the stock prices that have changed since the last update. We use the date concatenated with the current time, modulo 15 minutes (i.e. 9:30, 9:45, 10:00, 10:15, etc) as the row key, and each row stores all the price changes that occurred in the fifteen minute interval that starts at the time in the row key. Each column name is the time of a price change concatenated with the listing id of the price that changed. The contents of the column is a composite data structure with basic quote information (price, volume, open, high, low, close for the day). The columns have a time to live which is configurable (currently set to 30 minutes).
The daemon that updates solr calls a DAO with a start time and an end time. The DAO queries a range of columns in generally at most two rows to get all the price changes that occurred in the time interval. We have found this to be very fast, returning in 1-2 seconds or less, depending on the time range being queried.
The Time Sorted Quotes column family is a good example of the need in Cassandra to create new column families to support new (types of) queries. Although the Quotes column family could have been used to query all the prices for all stocks, it was not very efficient to use it, so it made sense to create a new column family that was better suited. The result is very efficient queries, at the cost of more development effort. In a relational database, we probably would have at least tried to index the time stamp column (it's a fair assumption that one exists) in a Quotes table and then we would have performed a range query on the index to fetch the rows that were updated in a certain time range. In some ways, the Time Sorted Quotes column family is the Cassandra equivalent of adding an index on timestamp. It is highly optimal, as quotes will be ordered on disk or in memory by time, whereas in the RDBMs solution, the quotes would not necessarily be arranged this way. The Cassandra solution is better in terms of efficiency (although only slightly if all data is kept in memory), scalability and redundancy. The RDBMS solution would be simpler to implement and perhaps more easily maintained.
The problem is that we have about 15,000 stocks whose price we potentially need to update. Even if we can query Cassandra for each stock price in about 2-3 ms (which is possible), the querying alone would take about 30-45 seconds, which is far too long when you need to provide real time stock prices. It would be possible to use multiple threads to query Cassandra and shrink this time considerably (parallel queries can work very well in Cassandra when you have more than one node in your cluster as your parallel queries potentially go to separate servers). However, we'd still have to update solr with 15,000 prices and, even with multiple threads, we would likely need more time than is ideal.
Fortunately, there is no real need to query Cassandra for 15,000 stock prices for each solr core update. Although a few stocks trade hundred of times per second and therefore have frequent price changes, most stock prices do not change often. We only need to update the prices of stocks that have changed since the last update, which is generally not a large number when the updates occur frequently.
The Time Sorted Quotes column family is used to query the stock prices that have changed since the last update. We use the date concatenated with the current time, modulo 15 minutes (i.e. 9:30, 9:45, 10:00, 10:15, etc) as the row key, and each row stores all the price changes that occurred in the fifteen minute interval that starts at the time in the row key. Each column name is the time of a price change concatenated with the listing id of the price that changed. The contents of the column is a composite data structure with basic quote information (price, volume, open, high, low, close for the day). The columns have a time to live which is configurable (currently set to 30 minutes).
The daemon that updates solr calls a DAO with a start time and an end time. The DAO queries a range of columns in generally at most two rows to get all the price changes that occurred in the time interval. We have found this to be very fast, returning in 1-2 seconds or less, depending on the time range being queried.
The Time Sorted Quotes column family is a good example of the need in Cassandra to create new column families to support new (types of) queries. Although the Quotes column family could have been used to query all the prices for all stocks, it was not very efficient to use it, so it made sense to create a new column family that was better suited. The result is very efficient queries, at the cost of more development effort. In a relational database, we probably would have at least tried to index the time stamp column (it's a fair assumption that one exists) in a Quotes table and then we would have performed a range query on the index to fetch the rows that were updated in a certain time range. In some ways, the Time Sorted Quotes column family is the Cassandra equivalent of adding an index on timestamp. It is highly optimal, as quotes will be ordered on disk or in memory by time, whereas in the RDBMs solution, the quotes would not necessarily be arranged this way. The Cassandra solution is better in terms of efficiency (although only slightly if all data is kept in memory), scalability and redundancy. The RDBMS solution would be simpler to implement and perhaps more easily maintained.
 |
| The Time Sorted Quotes column family. The row key is a time stamp for the beginning of a five minute interval. The columns in the row are the price changes for all stocks during that five minute interval. The column names are the time of day concatenated to the listing_id for the stock, which, using a String comparator, causes the columns to be sorted in order by time of day. The data in each column is just an easily parseable text blob with stock quote information. |
Closing Thoughts
Cassandra works extremely well for stock data, which is a type of time series data. The ability to have large numbers of dynamically created columns in a row which are kept in sorted order on disk and in memory is a really good fit. We have a "legacy" implementation that stores stock quotes in a relational database. Cassandra performs much better, especially on writes (more than 100x faster), which is important because stock data sometimes arrives quickly and needs to be persisted quickly if we are to present it in real time. Cassandra's ability to scale horizontally and its fault tolerance are also attractive because users of stock data expect current quotes and are intolerant of down time.
Great article. I'm working on a similar system, and I have a question.
ReplyDeleteInterval Quotes need high continuity rate in order to provide accurate charts, so how do you handle gaps in data when the data feed service is temporarily out?
Taking into account the considerable amount of data that might get lost in few seconds.
One important note about 'COMPACT STORAGE' in Cassandra. You should avoid this, see:
ReplyDeletehttps://www.datastax.com/documentation/cql/3.0/cql/ddl/ddl_legacy_tables_c.html
"You can create Thrift/CLI-compatible tables in CQL 3 using the COMPACT STORAGE directive. The compact storage directive used with the CREATE TABLE command provides backward compatibility with older Cassandra applications; new applications should generally avoid it. "
Another note: Never, never never use float (or Doubles) for financial calculations. Either use BigDecimal under Java or Ints and count the pennies. Otherwise you lost precision.
Deletehttp://javarevisited.blogspot.nl/2012/02/java-mistake-1-using-float-and-double.html